
Every time I call .backward() in PyTorch, gradients flow backward through millions of operations — each one applying calculus correctly without me writing a single derivative by hand. I used to treat that as magic. It isn’t. It’s the chain rule, a computation graph, and a walk in reverse order.
This post is one continuous walkthrough: why training needs gradients, the chain rule intuition, how expressions become graphs, a complete hand-derived backprop on $z = (x+y) \cdot y$ with $x=2$, $y=3$ where every gradient step gets its own line, then the ~80-line Python Value class that automates exactly that process. Same pipeline as numerical gradient checking — own the math before you trust the engine. Part of the ML Foundations series; if linear algebra is still fuzzy, start there.
By the end I’ll have a working autograd engine that can train a neural network on XOR.
Why do neural networks need derivatives?
Training a neural network means minimizing a loss function $L$ by nudging parameters in the direction that decreases $L$. That direction is the gradient: a vector of partial derivatives $\frac{\partial L}{\partial w_i}$ for every weight $w_i$.
For a network with millions of parameters, computing these derivatives by hand is impossible. I need a machine to do it.
Three approaches exist:
| Method | How | Problem |
|---|---|---|
| Symbolic diff | Algebra: manipulate expressions | Expression explosion |
| Numerical diff | Finite differences: $\frac{f(x+h) - f(x)}{h}$ | Slow, numerically unstable |
| Automatic diff | Track ops at runtime, apply chain rule | This is what we build |
Automatic differentiation (autograd) is exact (up to floating point), fast, and works for any Python control flow — loops, conditionals, recursion. When I finish the engine below, I’ll verify every backward() with numerical gradient checking before I trust it on anything harder than XOR.
graph LR
subgraph "Differentiation methods"
S["Symbolic\ndiff"] -->|"Expression\nexplosion"| X1["✗"]
N["Numerical\ndiff"] -->|"Slow +\nunstable"| X2["✗"]
A["Automatic\ndiff"] -->|"Exact +\nfast"| OK["✓"]
end
style A fill:#d4edda,stroke:#009900,color:#111
style OK fill:#d4edda,stroke:#009900,color:#111
style X1 fill:#f8d7da,stroke:#990000,color:#111
style X2 fill:#f8d7da,stroke:#990000,color:#111
What is the chain rule, and why is it enough?
Every neural network computation decomposes into elementary operations: add, multiply, exponentiate, ReLU, and so on. The chain rule tells me how to compose derivatives through a sequence of those operations.
If $L = f(g(x))$, then:
Read that right-to-left when doing backprop: start at the output, multiply by each local derivative as I walk toward the inputs.
More generally, for a node $v$ in a computation graph with successors $s_1, s_2, \ldots$:
where $\bar{v} = \frac{\partial L}{\partial v}$ is called the adjoint of $v$.
The sum matters. If one variable feeds two later operations — $y$ shows up in both $x+y$ and a multiply — its gradient receives contributions from both branches. I add them; I never overwrite.
That adjoint equation is the entire mathematical foundation. Everything below is implementation.
flowchart LR
L["Output L"] -->|"local ∂"| N3["Node 3"]
N3 -->|"local ∂"| N2["Node 2"]
N2 -->|"local ∂"| N1["Node 1"]
N1 -->|"local ∂"| X["Input x"]
style L fill:#d4edda,stroke:#009900,color:#111
What is a computation graph?
Every expression I write builds a directed acyclic graph (DAG) of operations. Nodes are values; edges are dependencies. Forward pass: walk from leaves to root, computing each node’s value. Backward pass: walk from root to leaves, distributing gradients via the chain rule.
Consider a slightly larger example before the main one:
a = 2.0
b = 3.0
c = a * b # c = 6
d = c + b # d = 9
L = d * 2 # L = 18
The graph looks like:
graph LR
a("a = 2.0") --> mul["× multiply"]
b("b = 3.0") --> mul
mul --> c("c = 6.0")
c --> add["+ add"]
b --> add
add --> d("d = 9.0")
d --> mul2["× 2"]
mul2 --> L("L = 18.0")
style L fill:#d4edda,stroke:#009900,color:#111
style a fill:#fff,stroke:#dddddd,color:#111
style b fill:#fff,stroke:#dddddd,color:#111
Leaf nodes (a, b) are inputs. The root (L) is the output. Every interior node must remember three things:
- Its value (forward pass result)
- Which children (parents in the dataflow sense) created it
- How to backprop gradients to those children — the local derivative rule for that operation
Notice b appears twice in this graph. When gradients flow backward, b accumulates contributions from both the multiply that produced c and the add that produced d. That accumulation pattern is not a bug — it’s the chain rule doing its job.
How do I backpropagate $z = (x+y) \cdot y$ by hand?
This is the example I wish someone had walked me through before I wrote any code. I will not skip a step.
Setup. Let $x = 2$, $y = 3$. Define an intermediate sum and the final output:
I am treating $z$ as the scalar “loss” at the top of the graph — the thing I want derivatives of with respect to $x$ and $y$.
Forward pass — every value on its own line
Substitute $x = 2$:
Substitute $y = 3$:
Compute the sum:
Compute the product:
Forward pass done. The graph in my head:
graph LR
x("x = 2") --> add["+ add"]
y("y = 3") --> add
add --> s("s = 5")
s --> mul["× multiply"]
y --> mul
mul --> z("z = 15")
style z fill:#d4edda,stroke:#009900,color:#111
style x fill:#fff,stroke:#dddddd,color:#111
style y fill:#fff,stroke:#dddddd,color:#111
y feeds two operations. That detail drives the backward pass.
Backward pass — every gradient on its own line
Reverse mode starts at the output. Seed the top node:
I will write $\bar{v} = \frac{\partial z}{\partial v}$ for short.
Step 1 — multiply node $z = s \cdot y$.
Local partial of $z$ with respect to $s$ (treat $y$ as constant):
Local partial of $z$ with respect to $y$ (treat $s$ as constant):
Chain rule from $z$ into $s$:
Chain rule from $z$ into $y$ through the multiply branch only:
Step 2 — add node $s = x + y$.
Local partial of $s$ with respect to $x$:
Local partial of $s$ with respect to $y$:
Chain rule from $s$ into $x$:
Chain rule from $s$ into $y$ through the add branch:
Step 3 — accumulate $\bar{y}$ from both branches.
$y$ appeared in the add and the multiply. Sum the adjoints:
Final answers
Sanity check with calculus. Expand $z = (x+y)y = xy + y^2$:
That hand walk is exactly what my Value.backward() will automate: seed the root with 1, visit nodes in reverse topological order, apply each operation’s local rule, accumulate with += when a variable appears more than once.
graph LR
subgraph "Backward order"
direction RL
z2["z\n∂z/∂z = 1"] --> mul2["×\n∂z/∂s=3, ∂z/∂y|mul=5"]
mul2 --> s2["s\n∂s/∂x=1, ∂s/∂y=1"]
s2 --> x2["x\n∂z/∂x = 3"]
s2 --> y2["y\n∂z/∂y = 5+3 = 8"]
mul2 --> y2
end
style z2 fill:#d4edda,stroke:#009900,color:#111
How do I build the Value class?
Now I wrap every scalar in a Value object. Each Value stores its data, its gradient, its parent nodes, and a closure _backward that knows how to distribute gradients to parents — encoding the local rules I just derived by hand.
classDiagram
class Value {
+float data
+float grad
+set _prev
+string _op
+_backward()
+__add__(other)
+__mul__(other)
+__pow__(exp)
+relu()
+backward()
}
note for Value "grad starts at 0.0\n_backward is a closure\nstored at creation time"
class Value:
def __init__(self, data, _children=(), _op=''):
self.data = float(data)
self.grad = 0.0
self._backward = lambda: None # no-op by default
self._prev = set(_children)
self._op = _op # for debugging
def __repr__(self):
return f"Value(data={self.data:.4f}, grad={self.grad:.4f})"
The grad field starts at zero. It accumulates contributions from all downstream nodes during the backward pass — the $\bar{y} = 5 + 3$ pattern from above.
Reproduce the hand example in code:
x = Value(2.0)
y = Value(3.0)
s = x + y # s.data == 5
z = s * y # z.data == 15
z.backward()
print(x.grad) # 3.0 ✓
print(y.grad) # 8.0 ✓ (5 from mul + 3 from add)
If either number is wrong, I do not move on. I run numerical gradient checking on that op until it matches to $10^{-5}$.
How does each operation define its local gradient?
For each operation, I do two things:
- Compute the output value (forward pass)
- Define a
_backwardclosure that accumulates gradients into the inputs using the chain rule
The closures are the machine-readable version of the hand derivation above.
Addition
Mathematically: if $c = a + b$, then $\frac{\partial c}{\partial a} = 1$ and $\frac{\partial c}{\partial b} = 1$.
So when the backward pass tells me $\frac{\partial L}{\partial c}$ (stored in c.grad), I accumulate:
That is exactly the $\bar{y}_{\text{add}} = \bar{s} \cdot 1$ step from the worked example.
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data + other.data, (self, other), '+')
def _backward():
self.grad += 1.0 * out.grad
other.grad += 1.0 * out.grad
out._backward = _backward
return out
Note the +=. A node can be used multiple times in a computation graph — gradients accumulate, they don’t overwrite.
Multiplication
If $c = a \cdot b$, then $\frac{\partial c}{\partial a} = b$ and $\frac{\partial c}{\partial b} = a$.
That is the $\bar{s} = \bar{z} \cdot y$ and $\bar{y}_{\text{mul}} = \bar{z} \cdot s$ step.
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data * other.data, (self, other), '*')
def _backward():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = _backward
return out
Power
If $y = x^n$, then $\frac{\partial y}{\partial x} = n \cdot x^{n-1}$.
def __pow__(self, exponent):
assert isinstance(exponent, (int, float))
out = Value(self.data ** exponent, (self,), f'**{exponent}')
def _backward():
self.grad += exponent * (self.data ** (exponent - 1)) * out.grad
out._backward = _backward
return out
ReLU
def relu(self):
out = Value(max(0, self.data), (self,), 'ReLU')
def _backward():
self.grad += (out.data > 0) * out.grad
out._backward = _backward
return out
Convenience wrappers
def __neg__(self): return self * -1
def __sub__(self, other): return self + (-other)
def __truediv__(self, other): return self * other**-1
def __radd__(self, other): return self + other
def __rmul__(self, other): return self * other
def __rsub__(self, other): return other + (-self)
The r variants handle expressions like 2 * v where the left operand is a Python number.
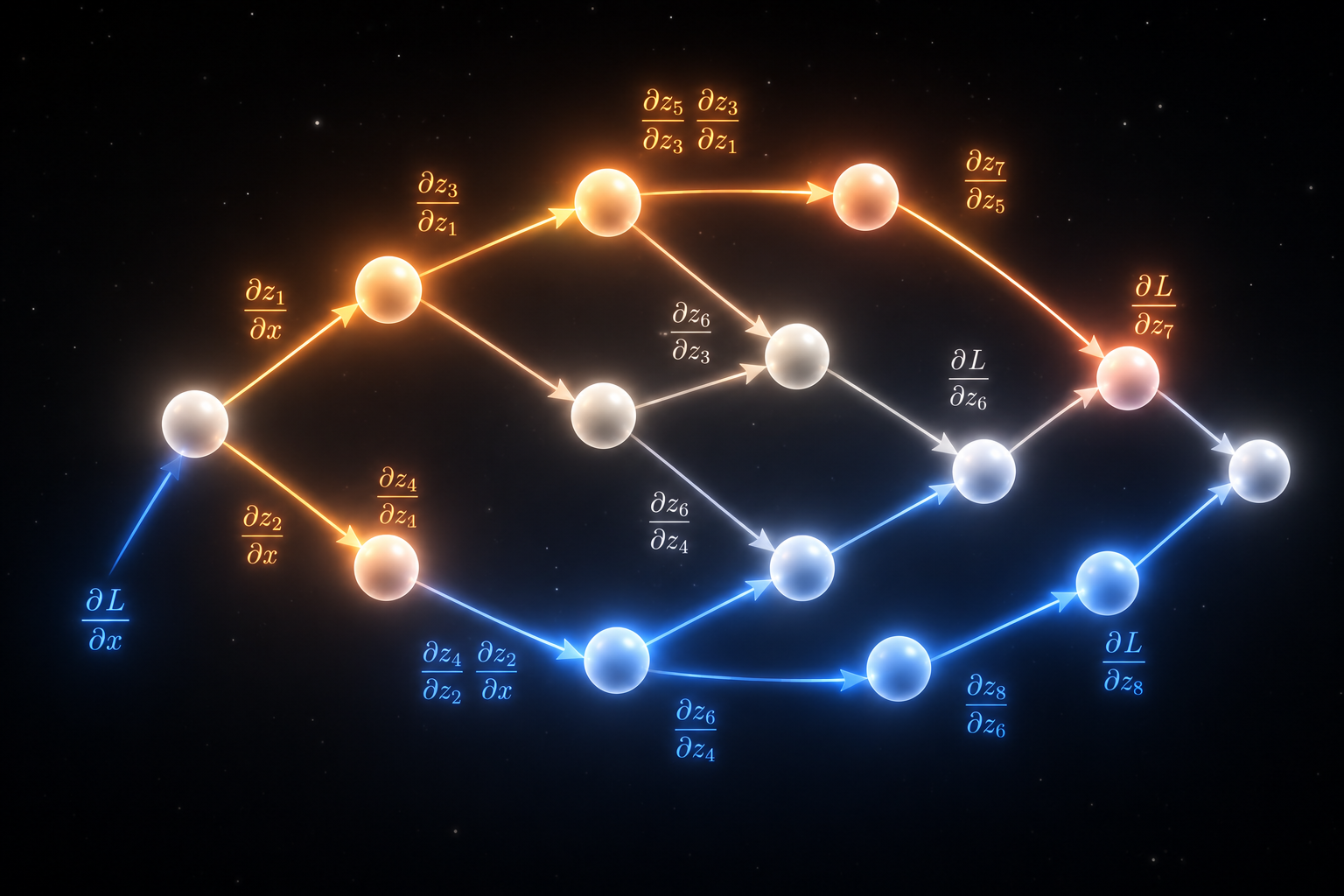
How does the backward pass visit nodes in the right order?
The hand derivation assumed I already knew $\bar{s}$ before I computed $\bar{x}$ and $\bar{y}_{\text{add}}$. That ordering is not optional.
Right order means: before processing a node, all nodes that depend on it must already have their gradients computed. That is exactly reverse topological order.
graph LR
subgraph "Forward order (topo)"
direction LR
A["a"] --> C["c=a*b"] --> E["L=c+b"]
B["b"] --> C
B --> E
end
subgraph "Backward order (reversed)"
direction RL
E2["L"] --> C2["c"] --> A2["a"]
E2 --> B2["b"]
C2 --> B2
end
style E fill:#d4edda,stroke:#009900,color:#111
style E2 fill:#d4edda,stroke:#009900,color:#111
For $z = (x+y) \cdot y$, backward visits: $z \to$ multiply $\to$ $s \to$ add $\to$ $x$, $y$. The multiply’s _backward runs before the add’s _backward can finish propagating into $y$ — but both write to y.grad with +=, so order among siblings does not matter; what matters is that z.grad is set before the multiply closure reads it.
I find the order with a depth-first search, then walk it in reverse:
def backward(self):
topo = []
visited = set()
def build_topo(v):
if v not in visited:
visited.add(v)
for child in v._prev:
build_topo(child)
topo.append(v)
build_topo(self)
# Seed: dL/dL = 1
self.grad = 1.0
for node in reversed(topo):
node._backward()
The DFS appends a node after recursing into its children — so topo comes out in topological order (leaves first, root last). I reverse it so I start at the root and work toward leaves.
What does the full autograd engine look like?
All the pieces in one place — 82 lines:
class Value:
def __init__(self, data, _children=(), _op=''):
self.data = float(data)
self.grad = 0.0
self._backward = lambda: None
self._prev = set(_children)
self._op = _op
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data + other.data, (self, other), '+')
def _backward():
self.grad += out.grad
other.grad += out.grad
out._backward = _backward
return out
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data * other.data, (self, other), '*')
def _backward():
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = _backward
return out
def __pow__(self, exponent):
out = Value(self.data ** exponent, (self,), f'**{exponent}')
def _backward():
self.grad += exponent * (self.data ** (exponent - 1)) * out.grad
out._backward = _backward
return out
def relu(self):
out = Value(max(0, self.data), (self,), 'ReLU')
def _backward():
self.grad += (out.data > 0) * out.grad
out._backward = _backward
return out
def backward(self):
topo, visited = [], set()
def build_topo(v):
if v not in visited:
visited.add(v)
for child in v._prev: build_topo(child)
topo.append(v)
build_topo(self)
self.grad = 1.0
for node in reversed(topo):
node._backward()
def __neg__(self): return self * -1
def __sub__(self, other): return self + (-other)
def __truediv__(self, other): return self * other**-1
def __radd__(self, other): return self + other
def __rmul__(self, other): return self * other
def __repr__(self):
return f"Value(data={self.data:.4f}, grad={self.grad:.4f})"
That is the entire engine. The three moving parts:
Value— wraps a scalar, storesgradand a_backwardclosure- Operation overloads — each op computes output and registers its local gradient rule
backward()— topological sort + chain rule traversal from root to leaves
Everything in PyTorch, JAX, and every other framework is this idea scaled up to tensors and compiled to run on GPUs.
How do I verify the engine against calculus?
The $z = (x+y) \cdot y$ example was the pedagogical walkthrough. Here is a slightly richer check — enough ops to catch a sign error or a forgotten +=.
Let $L = (a \cdot b + c)^2$ with $a=2$, $b=3$, $c=1$.
Forward pass:
By hand:
a = Value(2.0)
b = Value(3.0)
c = Value(1.0)
L = (a * b + c) ** 2
L.backward()
print(a.grad) # 42.0 ✓
print(b.grad) # 28.0 ✓
print(c.grad) # 14.0 ✓
Before I stack layers on top, I run numerical gradient checking on each new op — pow, relu, then the neuron — so I never debug a training loop when the real bug is a single wrong partial three ops down.
How do I build a neural network on top?
With gradients working, I can build neurons and layers. A single neuron computes $y = \text{ReLU}(w \cdot x + b)$ for a weight vector $w$ and bias $b$.
graph TD
subgraph "MLP(2, [4, 4, 1])"
I1((x₁)) & I2((x₂))
subgraph "Layer 1 — 4 neurons"
N1((n)) & N2((n)) & N3((n)) & N4((n))
end
subgraph "Layer 2 — 4 neurons"
N5((n)) & N6((n)) & N7((n)) & N8((n))
end
subgraph "Output — 1 neuron"
OUT((y))
end
I1 & I2 --> N1 & N2 & N3 & N4
N1 & N2 & N3 & N4 --> N5 & N6 & N7 & N8
N5 & N6 & N7 & N8 --> OUT
end
style OUT fill:#d4edda,stroke:#009900,color:#111
import random
class Neuron:
def __init__(self, n_inputs):
self.w = [Value(random.uniform(-1, 1)) for _ in range(n_inputs)]
self.b = Value(0.0)
def __call__(self, x):
activation = sum(wi * xi for wi, xi in zip(self.w, x)) + self.b
return activation.relu()
def parameters(self):
return self.w + [self.b]
class Layer:
def __init__(self, n_inputs, n_outputs):
self.neurons = [Neuron(n_inputs) for _ in range(n_outputs)]
def __call__(self, x):
return [n(x) for n in self.neurons]
def parameters(self):
return [p for n in self.neurons for p in n.parameters()]
class MLP:
def __init__(self, n_inputs, layer_sizes):
sizes = [n_inputs] + layer_sizes
self.layers = [Layer(sizes[i], sizes[i+1]) for i in range(len(layer_sizes))]
def __call__(self, x):
for layer in self.layers:
x = layer(x)
return x[0] if len(x) == 1 else x
def parameters(self):
return [p for layer in self.layers for p in layer.parameters()]
Each Neuron.__call__ builds a fresh computation graph. Every Value in that graph remembers its parents; loss.backward() walks the whole tree.
How do I train the network?
XOR is the classic sanity check — not linearly separable, so a single neuron fails, but a small MLP with ReLU should learn it.
# XOR dataset
X = [[0,0], [0,1], [1,0], [1,1]]
y = [0, 1, 1, 0 ]
model = MLP(2, [4, 4, 1])
for step in range(100):
# Forward pass
preds = [model(x) for x in X]
# Mean squared error loss
loss = sum((pred - target)**2 for pred, target in zip(preds, y))
# Backward pass
for p in model.parameters():
p.grad = 0.0 # zero gradients before backward
loss.backward()
# Gradient descent
for p in model.parameters():
p.data -= 0.05 * p.grad
if step % 10 == 0:
print(f"step {step:3d} | loss {loss.data:.4f}")
Output (approximate):
step 0 | loss 2.1847
step 10 | loss 1.3204
step 20 | loss 0.8951
step 30 | loss 0.5623
...
step 90 | loss 0.0412
The loss drops. The engine is computing real gradients — the same chain rule I traced by hand on $z = (x+y) \cdot y$, now running thousands of times per second inside a training loop.
How is PyTorch different from this engine?
My engine works on scalars. PyTorch operates on tensors (n-dimensional arrays) — the same idea, vectorised with C++/CUDA under the hood. The concepts map exactly:
graph LR
subgraph "Our engine"
V["Value\n(scalar float)"] --> VD["value.data"]
V --> VG["value.grad"]
V --> VB["value._backward\n(closure)"]
V --> VP["value._prev\n(set of parents)"]
end
subgraph "PyTorch"
T["Tensor\n(n-dim array)"] --> TD["tensor.data"]
T --> TG["tensor.grad"]
T --> TB["tensor.grad_fn\n(C++ Function obj)"]
T --> TP["grad_fn.next_functions\n(tuple of parents)"]
end
V -. "same concept\nscaled up" .-> T
style V fill:#fff,stroke:#dddddd,color:#111
style T fill:#d4edda,stroke:#009900,color:#111
| Our engine | PyTorch |
|---|---|
Value.data |
tensor.data |
Value.grad |
tensor.grad |
Value._backward |
tensor.grad_fn |
Value._prev |
tensor.grad_fn.next_functions |
loss.backward() |
loss.backward() |
p.grad = 0.0 |
optimizer.zero_grad() |
The key difference: PyTorch’s DAG stores functions (AddBackward, MulBackward, etc.) not values. But the topological traversal and chain rule application are identical.
When I eventually move to tensors in my own projects, I still gradient-check every custom backward() before I trust it at scale.
What pitfalls should I watch for?
Forgetting to zero gradients. Because grad accumulates with +=, calling .backward() twice without zeroing will double-count. I always zero before each backward pass.
Reusing leaf nodes. If y appears in both $x+y$ and $s \cdot y$, its gradient correctly receives contributions from both branches via accumulation. That is the $\bar{y} = 5 + 3$ pattern — a feature, not a bug.
In-place operations. Modifying .data directly after using a value in a computation breaks the graph. Never do v.data = new_val mid-computation.
Circular graphs. The topological sort assumes a DAG. Feedback loops aren’t supported (and shouldn’t be — use RNNs through time which unroll into a DAG).
Skipping verification. Hand math on $z = (x+y) \cdot y$ is not optional pedagogy. If I cannot get $\partial z / \partial y = 8$ by hand, my __mul__ or __add__ implementation will be wrong and I will not know until the loss curve looks “almost right.” Numerical gradient checking catches that in seconds.
How does a longer backward pass look by hand?
The $z = (x+y) \cdot y$ example covered add, multiply, and accumulation. Here is a second complete pass with power and a reused variable — the same three ingredients, more nodes.
Let $a=2$, $b=-3$, $c=10$, and
Backward — every gradient on its own line.
Seed:
Power node $L = e^2$:
Add node $e = d + c$:
Multiply node $d = a \cdot b$:
Reverse mode is ideal for neural networks because one scalar loss can produce gradients for millions of parameters in roughly one backward traversal. Its main cost is memory: forward intermediates must be retained or recomputed.
Where does this fit in the series?
| Order | Post | What it covers |
|---|---|---|
| 1 | Linear algebra foundations | Vectors, matrices, eigenvalues — the notation autograd operates on |
| 2 | This post | Chain rule, computation graphs, Value, backprop |
| 3 | Numerical gradient checking | Finite-difference verification of every backward() |
| 4 | Byte pair encoding | Tokenizer pipeline before the model |
| 5 | Token embeddings | Discrete tokens → continuous vectors |
| 6 | Positional encoding | Order information in transformers |
The whole autograd idea in one sentence: wrap every number in an object that remembers how it was created, then walk creation history in reverse applying the chain rule.
I did not understand .backward() until I could get $\partial z / \partial y = 8$ on paper for $z = (x+y) \cdot y$. After that, the 82-line engine was almost boring — which is exactly what I want from infrastructure.
Watch it built live
Andrej Karpathy’s lecture that inspired this post — he builds micrograd from scratch in real time:
References
Primary sources — code and implementations
-
Karpathy, A. (2020). micrograd: A tiny scalar-valued autograd engine. GitHub. https://github.com/karpathy/micrograd
-
Karpathy, A. (2022). The spelled-out intro to neural networks and backpropagation: building micrograd. YouTube, Neural Networks: Zero to Hero series. https://www.youtube.com/watch?v=VMj-3S1tku0
-
Smit, J. (2022). DIY auto-grad engine: A step-by-step guide to calculating derivatives automatically. jordismit.com. https://jordismit.com/blog/diy-auto-grad-engine-a-step-by-step-guide-to-calculating-derivatives-automatically/
-
Loh, J. (2024). Reverse-mode autodiff from scratch. jlohding.github.io. https://jlohding.github.io/posts/autodiff/
-
Sankhla, B. (2023). DIY Deep Learning: Crafting your own autograd engine from scratch. Medium / SFU CSPMP. https://medium.com/sfu-cspmp/diy-deep-learning-crafting-your-own-autograd-engine-from-scratch-for-effortless-backpropagation-ddab167faaf5
Official documentation
-
PyTorch. Automatic Differentiation with torch.autograd. PyTorch Tutorials. https://docs.pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html
-
JAX. Forward- and reverse-mode autodiff in JAX. JAX Documentation. https://docs.jax.dev/en/latest/jacobian-vector-products.html
-
Dive into Deep Learning. 2.5 Automatic Differentiation. d2l.ai. https://d2l.ai/chapter_preliminaries/autograd.html
Theory
-
Wikipedia. Automatic differentiation. Wikimedia Foundation. https://en.wikipedia.org/wiki/Automatic_differentiation
-
University of Amsterdam. Module 3: The Reverse Mode of Automatic Differentiation. auto-ed.readthedocs.io. https://auto-ed.readthedocs.io/en/latest/mod3.html
Support the writing
If this post helped, a coffee keeps the deep dives, paper picks, and news digests coming.
Buy Me a Coffee